"
3. Introducción y montado de una arquitectura de producción
En el contexto de las aplicaciones web, las arquitecturas de producción no solo cuentan con un Tomcat al que todos los clientes atacan, sino que suele ser algo más parecido a la imagen siguiente, y es muy parecida a la que vamos a montar en este tutorial.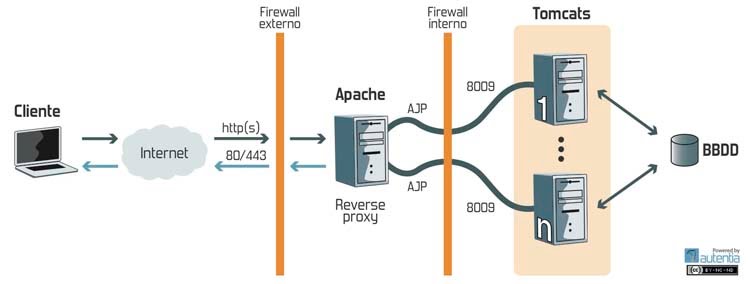 Esto se hace así por varios motivos:
Esto se hace así por varios motivos:
- Primero porque teniendo un Apache delante del Tomcat, se puede servir el contenido estático directamente por él, ya que es para esto para lo que mejor nos sirve un apache, y reducimos la carga en el Tomcat.
- Segundo porque lo podemos utilizar para balancear entre distintos Tomcats, por si necesitamos un sistema de alta disponibilidad o simplemente porque el número de usuarios en concurrencia requiere dos máquinas.
Descargamos el Apache Tomcat. Simplemente lo descomprimimos en el directorio que queramos. Podéis utilizar el comando tar -xvf nombre_del_archivo.tar.gz
Como vamos a hacer pruebas sobre una aplicación Web ( cortesía de Francisco Javier ), os la voy pasando para comprobar que la instalación del Tomcat ha sido correcta. Os podéis descargar la aplicación Web del siguiente enlace.
Como veis es un zip que contiene un war ,un fichero c3p0.properties y un mysql-connector-java-5.1.11.jar. El archivo war lo copiais en la carpeta /TOMCAT_HOME/webapps/, en donde /TOMCAT_HOME/ es el directorio en el que habéis instalado el Tomcat. Los archivos c3p0.properties y mysql-connector-java-5.1.11.jar los copiais en /TOMCAT_HOME/lib/. Los más avispados de la clase se habrán dado cuenta de que vamos a utilizar base de datos. Para el ejemplo vamos a usar MySql. Os la podéis descargar del siguiente enlace.
Vamos a necesitar una base de datos con tan solo una tabla, aquí os dejo el script para que podáis crearosla fácilmente.
Ahora vamos a montar el Apache. Con mi sistema operativo tengo ya instalado uno, asique es el que voy a utilizar. Si estás utilizando un sistema operativo Unix puedes descargártelo con el comando apt-get install apache2 y si etás en Windows te lo puedes bajar de este enlace.
Ya tenemos los dos servidores montados y funcionando. Ahora vamos a conectarlos mediante el protocolo AJP 1.3 con mod_proxy. Abrimos primero el archivo /TOMCAT_HOME/conf/server.xml. Por defecto el Tomcat viene configurado para que el apache se pueda conectar a él mediante el puerto 8009, como podéis ver en la siguiente línea:
Añadimos las siguientes líneas al final del fichero /APACHE_HOME/httpd.conf
Quiero aconsejaros un par de páginas de la documentación de mod_proxy por si os queda alguna duda o queréis ampliar algún concepto:
- http://httpd.apache.org/docs/2.2/mod/mod_proxy.html
- http://httpd.apache.org/docs/2.2/mod/mod_proxy_ajp.html

A partir de ahora vamos a necesitar JMeter, ya que vamos a simular carga en la aplicación para ver distintas situaciones y como podríamos arreglarlas. Podéis descargalo desde la página oficial.
Una vez lo tenemos instalado vamos a hacerle unos cambios ya que le vamos a meter un poco de caña y vamos a necesitar más memoria de la que trae configurada por defecto. Editamos el fichero /JMETER_HOME/bin/jmeter.
Aquí tenéis un plan de pruebas sencillito que me he creado grabando una navegación por la aplicación web. Si queréis saber como se hace esto, aquí tenéis un tutorial que lo explica muy bien: JMeter, pruebas de stress sobre aplicaciones web: Grabando y reproduciendo navegaciones
Vamos a necesitar también AppDynamics Lite para ver donde se nos va el tiempo. Aquí os dejo un tutorial que explica perfectamente como os lo podéis descargar e instalar: AppDynamics Lite, encontrar problemas de rendimiento en aplicaciones Java en un entorno de producción
Pues nada, ejecutamos JMeter con el comando ./JMETER_HOME/bin/jmeter.sh y pinchamos en abrir y seleccionamos el plan de pruebas que os acabais de descargar (pruebas.jmx). Sin más dilación le damos al play y nos posicionamos en Informe Agregado.
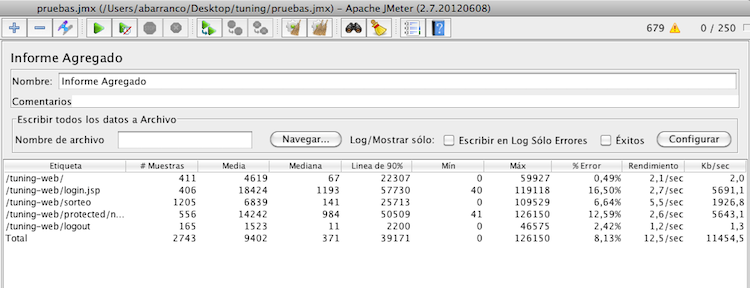
A medida que más usuarios están haciendo peticiones el tiempo máximo de cada petición sube. Ahora mismo tenemos 250 usuarios creando participantes y sorteando premios entre ellos, mientras se logan y se salen de la aplicación.
Tras un breve tiempo ya empiezan a aparecer los primeros errores, como puede verse en la imagen
 Abrimos también un navegador y accedemos a la consola de
AppDynamics en: http://localhost:8990/. Podemos observar por ejemplo
peticiones de este tipo.
Abrimos también un navegador y accedemos a la consola de
AppDynamics en: http://localhost:8990/. Podemos observar por ejemplo
peticiones de este tipo.
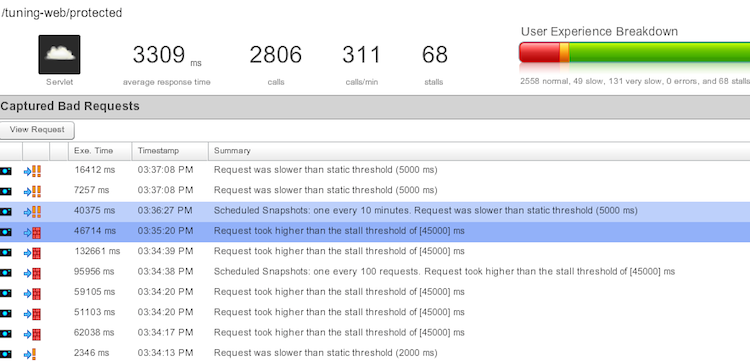
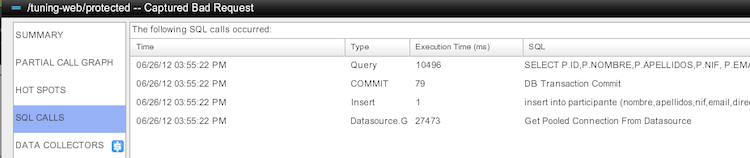
- Estamos gestionando mal las conexiones a la base de datos. No las cerramos, abrimos más de la cuenta …
- Tenemos un pool de conexiones que no aguanta 250 usuarios en concurrencia.
3.1 Configuración del pool de conexiones a la base de datos
La configuración a la base de datos la tenemos precisamente en el archivo c3p0.properties que copiamos en /TOMCAT_HOME/lib. Si abrimos este fichero, vemos como tenemos seteado el atributo c3p0.maxPoolSize a tan solo 10 conexiones. Vamos a probar a aumentar el atributo a 100, reiniciamos el Tomcat y repetimos la prueba. Esta vez vamos a monitorizar también con jconsole, por lo que abrimos un terminal y simplemente con el comando jconsole, se nos abrirá esta herramienta.Seleccionamos el servidor Tomcat en la lista y damos a conectar.
 En la siguiente imagen vemos como se ha aumentado el rendimiento tras el cambio a las 100 conexiones.
En la siguiente imagen vemos como se ha aumentado el rendimiento tras el cambio a las 100 conexiones.
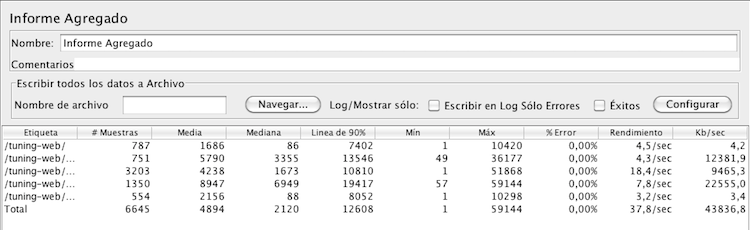 El rendimiento se ha aumentado en un 300%, y ya no hay errores. Podemos ver lo importante que es este parámetro. Para sacar este dato lo que tenéis que comparar es el rendimiento (también llamado throughput) de la primera prueba (12,5 por segundo) con el de la segunda (37,8 por segundo).
El rendimiento se ha aumentado en un 300%, y ya no hay errores. Podemos ver lo importante que es este parámetro. Para sacar este dato lo que tenéis que comparar es el rendimiento (también llamado throughput) de la primera prueba (12,5 por segundo) con el de la segunda (37,8 por segundo).
Si nos fijamos ahora en AppDynamics podemos ver que hay algunas consultas que están tardando mucho en obtener una respuesta, pero ya no es por obtener el pool de conexiones. Por la propia prueba de la aplicación y por la aplicación en si, tenemos que 250 usuarios están continuamente consultando y escribiendo en UNA sola tabla, por lo que se va mucho tiempo en la gestión de la transaccionalidad, como es lógico. Si abrís las consultas SQL que se ejecutan en las peticiones lo podéis observar. Aquí no podemos hacer nada.
 Vamos a ver si los resultados de jConsole nos dicen algo más.
Vamos a ver si los resultados de jConsole nos dicen algo más.
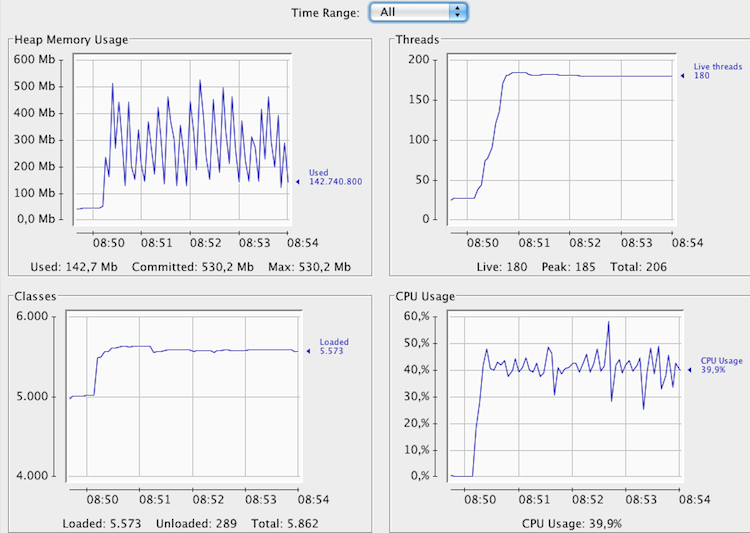 Viendo esta gráfica podemos decir a simple vista 3 cosas:
Viendo esta gráfica podemos decir a simple vista 3 cosas:
- Primero: que la aplicación está gestionando bien la memoria (no parece haber memory leaks). Si veis la gráfica de Heap Memory Usage, está en serrucho, lo que indica que se libera memoria de forma correcta. Si tuviera una pendiente ascendiente, que no se recupera la memoria … podríamos pensar que tenemos memory leaks Hemos llegado al pico de memoria, que lo tenemos puesto en 512 MB en 3 ocasiones, lo que nos hace ver que el uso de memoria es intensivo. Un aumento de esta podría beneficiar el rendimiento de la aplicación.
- Segundo: que la CPU va muy relajada. Es decir, si fuera por la CPU se podrían poner en estas condiciones otros 250 usuarios. Ahora mismo vamos a ver que en realidad tenemos otro cuello de botella que hace que no estemos con 250 usuarios.
- Tercero: que pese a lanzar la prueba con 250 usuarios el Tomcat solo tiene 180 threads funcionando, es decir, estos 80 hilos que faltan podrían estarse quedando en el Apache. Tenemos otro cuello de botella, vamos a ver si como sospechamos es el Apache.
3.2 Configuración de Threads de Apache y Tomcat
Vamos a probar a aumentar el número de Threads que puede atender el Apache. Lo primero que tenemos que hacer es, ver en que modo se está ejecutando nuestro servidor Apache. Para ello ejecutamos el siguiente comando en un terminal httpd -V. Este comando es válido tanto para Windows, como para Mac, em cambio si estás siguiendo el tutorial y haciendo las pruebas con un sistema operativo Linux el comando sería apache2 -V. El resultado sería algo parecido a lo siguiente: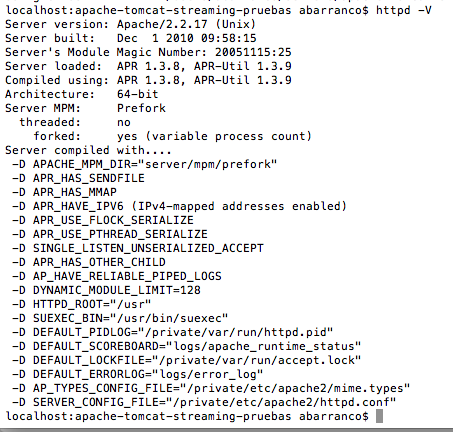 podéis consultar la documentación oficial sobre los módulos de multiproceso (MPM) en el siguiente enlace. En esta página básicamente nos está diciendo que los modos por defecto para sistemas Unix es prefork (tal y como nos decía httpd -V), y para sistemas Windows es WinNT. Si pinchamos en el enlace que se nos ofrece para MPM prefork, nos están diciendo que el número de hilos que ofrecen por defecto es 256.
El cuello de botella entonces no está en Apache !!!. Tiene que estar en
el Tomcat. También nos dicen que si necesitamos ampliarlo o
decrementarlo, la directiva que tenemos que usar es MaxClients. ¡OJO! los usuarios de windows, que la directiva es distinta, os la chivo, para sistemas Windows la directiva es ThreadsPerChild.
Parámetros como estos, yo los considero importantes, y aunque por
defecto se sirven 256 hilos, a mi me gusta poner la directiva en el
Apache, ya que hoy me acuerdo que son 256 porque lo acabo de mirar en la
documentación. Dentro de un mes seguro que no me acuerdo, asique para
no tener que volver a buscarlo, voy a editar el fichero http.conf para añadir lo siguiente: MaxClients 300. Voy a poner 300 para no dejarlo justo a 250 sino tener un pequeño margen. Reiniciamos el Apache.
podéis consultar la documentación oficial sobre los módulos de multiproceso (MPM) en el siguiente enlace. En esta página básicamente nos está diciendo que los modos por defecto para sistemas Unix es prefork (tal y como nos decía httpd -V), y para sistemas Windows es WinNT. Si pinchamos en el enlace que se nos ofrece para MPM prefork, nos están diciendo que el número de hilos que ofrecen por defecto es 256.
El cuello de botella entonces no está en Apache !!!. Tiene que estar en
el Tomcat. También nos dicen que si necesitamos ampliarlo o
decrementarlo, la directiva que tenemos que usar es MaxClients. ¡OJO! los usuarios de windows, que la directiva es distinta, os la chivo, para sistemas Windows la directiva es ThreadsPerChild.
Parámetros como estos, yo los considero importantes, y aunque por
defecto se sirven 256 hilos, a mi me gusta poner la directiva en el
Apache, ya que hoy me acuerdo que son 256 porque lo acabo de mirar en la
documentación. Dentro de un mes seguro que no me acuerdo, asique para
no tener que volver a buscarlo, voy a editar el fichero http.conf para añadir lo siguiente: MaxClients 300. Voy a poner 300 para no dejarlo justo a 250 sino tener un pequeño margen. Reiniciamos el Apache.
Vamos a ver entonces el número de hilos que tiene configurado el Tomcat.
Como estamos conectando Apache con Tomcat, voy a leerme primero la documentación de AJP 1.3, a ver donde se puede cambiar este parámetro. Esta es la documentación de AJP 1.3 para Tomcat 7. En maxThreads nos está diciendo que podemos setear el número máximo de hilos que va a crear este conector, o sea el número de peticiones simultaneas que vamos a poder atender. Por defecto son 200. Además nos dice que si tenemos definido un executor y está asociado con este conector este atributo se ignora y se usa el del executor. Si nos vamos al fichero /TOMCAT_HOME/conf/server.xml, vemos que efectivamente tenemos definido un executor.
 … y que algunos conectores lo tienen asociado …
… y que algunos conectores lo tienen asociado …
 … pero nuestro conector no lo está usando, asique le setemos el
atributo maxThreads de nuevo a 300 para dejarnos un margen. Debería
quedarnos de la siguiente forma:
… pero nuestro conector no lo está usando, asique le setemos el
atributo maxThreads de nuevo a 300 para dejarnos un margen. Debería
quedarnos de la siguiente forma:
 … reiniciamos el Tomcat.
… reiniciamos el Tomcat.También hay otro parámetro a nivel de configuración del proxy en el Apache, que me parece importantísimo. Lo podéis ver en este enlace. Me refiero al parámetro retry. Tal y como veis en la documentación este parámetro está puesto por defecto a 60 segundos, lo que significa que cuando el Tomcat nos devuelve en una petición un error, Apache no le va a mandar más peticiones en 60 segundos. Esto puede pasar en picos altos de uso, en los que hay muchos usuarios y el Tomcat nos devuleve un timeout para una de ellas. No ha sido capaz de atender la petición y nos devuelve un error. Con la configuración por defecto tardaríamos 60 segundos en volver a mandar peticiones. Este tiempo es excesio y provoca que tengamos un rendimiento menor, si haceis pruebas con muchos usuarios observaréis que las peticiones van como en ráfagas y que hay tiempos en que la CPU está con un rendimiento del 0%, es porque cuando una petición falla tarda un rato en volver a mandar nuevas, y mientras tanto el servidor está totalmente relajado. Vamos a poner este parámetro a 5 segundos y vamos a ver como el rendimiento aumenta considerablemente. Editamos el fichero /APACHE_HOME/http.conf y añadimos retry=5 a la configuración del ProxyPass. Nos debería quedar de la siguiente forma:
 … reiniciamos el Apache.
… reiniciamos el Apache.Pues nada, vamos a darle caña de nuevo con 250 usuarios a ver como afectan estos cambios al rendimiento.
Vamos a analizar primero las gráficas que nos muestra el jConsole.
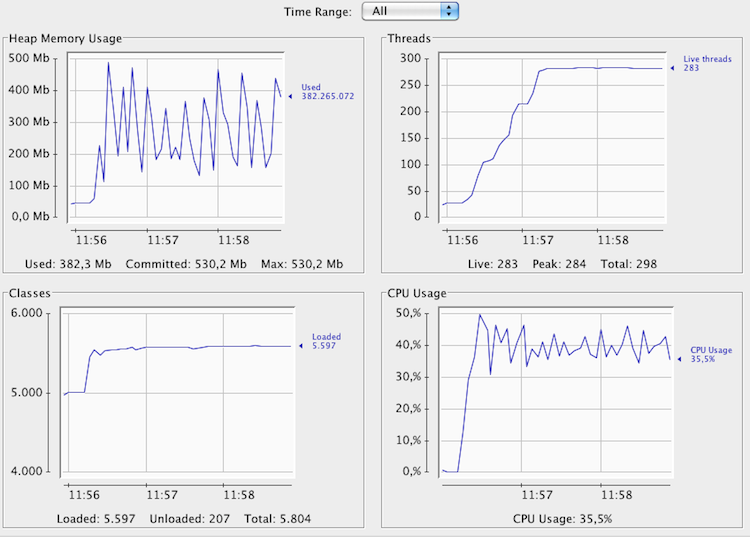 Podemos sacar varias conclusiones:
Podemos sacar varias conclusiones:- Primero: La CPU tiene prácticamente el mismo uso que en la prueba anterior. Esto es debido a que con 180 hilos o con 280 está trabajando lo mismo, es decir, está trabajando poco. Aquí quien está trabajando es la BBDD, ya que la aplicación es muy sencillita y lo único que hace es persistir usuarios en la misma tabla de base de datos. En un caso normal de aplicación tendréis más tablas, entrada/salida, algoritmos más complicados y estas optimizaciones os pondrán la CPU al 100%, y os subirán el rendimiento en un alto porcentaje.
- Segundo: Hemos conseguido los 250 usuarios en concurrencia, pero vemos que lo que realmente estamos midiendo aquí es la transaccionalidad sobre una tabla gestionada por MySQL, es decir, la base de datos no da para más. No podemos gestionar concurrencia y exclusión mutua sobre una tabla a más velocidad para 250 usuarios. Seguramente el rendimiento óptimo no sea con 250 usuarios. Antes teníamos unos 150 y teníamos más rendimiento. Para ver los usuarios en concurrente os tenéis que fijar en el número de threads que son 250 del JMeter + X threads que usa el Tomcat internamente = 283 Live threads.
 Los resultados del JMeter van en consonancia. Ahora tenemos más usuarios, pero la base de datos es la misma,
y seguimos insertando datos en una tabla, luego habiendo más usuarios a
la vez tardaremos más, porque hay que gestionar más usuarios
concurrentes, y el rendimiento en consecuencia baja. Hay que tener claro
que el punto óptimo de una aplicación para una configuración
determinada es X usuarios. Si te pasas de esos usuarios el rendimiento
decrece, lo que no quiere decir que necesariamente la aplicación no
escale, sino que tienes que adapatar la configuración a ello, por eso lo
primero que tienes que tener claro es el número de usuarios máximo que
se espera en una aplicación, para configurar que la aplicación tenga un
comportamiento óptimo para ese número. Si luego se meten el doble de usuarios es obvio que el rendimiento decrecerá.
Los resultados del JMeter van en consonancia. Ahora tenemos más usuarios, pero la base de datos es la misma,
y seguimos insertando datos en una tabla, luego habiendo más usuarios a
la vez tardaremos más, porque hay que gestionar más usuarios
concurrentes, y el rendimiento en consecuencia baja. Hay que tener claro
que el punto óptimo de una aplicación para una configuración
determinada es X usuarios. Si te pasas de esos usuarios el rendimiento
decrece, lo que no quiere decir que necesariamente la aplicación no
escale, sino que tienes que adapatar la configuración a ello, por eso lo
primero que tienes que tener claro es el número de usuarios máximo que
se espera en una aplicación, para configurar que la aplicación tenga un
comportamiento óptimo para ese número. Si luego se meten el doble de usuarios es obvio que el rendimiento decrecerá.
Con este tutorial hemos visto como interpretar las gráficas, e identificar posibles cuellos de botella. Me gustaría animar a los lectores a probar una aplicación desarrollada por ellos para ver su comportamiento e intentar ajustar la configuración para optimizarlo todo lo posible. Hay otros parámetros que podéis configurar para aumentar el rendimiento de vuestra aplicación. Os recomiendo este enlace.